

数据采集又叫网络爬虫/蜘蛛,是一个自动提取网页的程序。搜索引擎之所以能保存那么多网页,就是不断地收录各种网页,并定时去采集最新信息。
常见的爬虫软件windows版本有八爪鱼、Octoparse、火车头等,高级功能需要收费,甚至连WordPress这类插件都有。还有各种语言的采集工具。这里介绍一个介绍一个专门采集微信公众号的工具,基于 Python 2.7 + firefox 36.0 ,模拟正常人访问搜狗搜索,来采集微信公众号数据。文章源自很文博客https://www.hinwi.com/很文博客-https://www.hinwi.com/11186.html
0.为什么采集
原因多多,可能是想找点好内容推荐或者转发,也有可能是收藏文章内容,数据采样、分析、整理。对于内容站点来说,更多的是获取最新,最热的关键字,没东西写的时候,转载一波。文章源自很文博客https://www.hinwi.com/很文博客-https://www.hinwi.com/11186.html
1.界面预览
1) 要爬取的微信公众号列表文章源自很文博客https://www.hinwi.com/很文博客-https://www.hinwi.com/11186.html
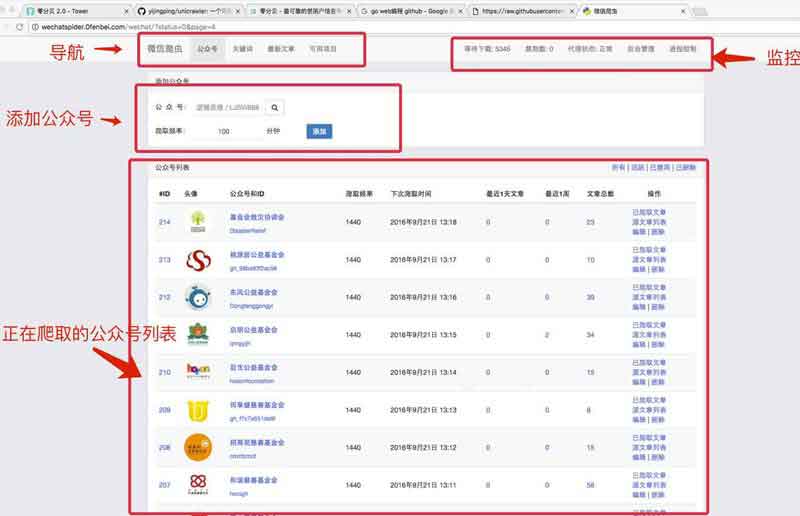 文章源自很文博客https://www.hinwi.com/很文博客-https://www.hinwi.com/11186.html
文章源自很文博客https://www.hinwi.com/很文博客-https://www.hinwi.com/11186.html
2) 要爬取的文章关键字列表文章源自很文博客https://www.hinwi.com/很文博客-https://www.hinwi.com/11186.html
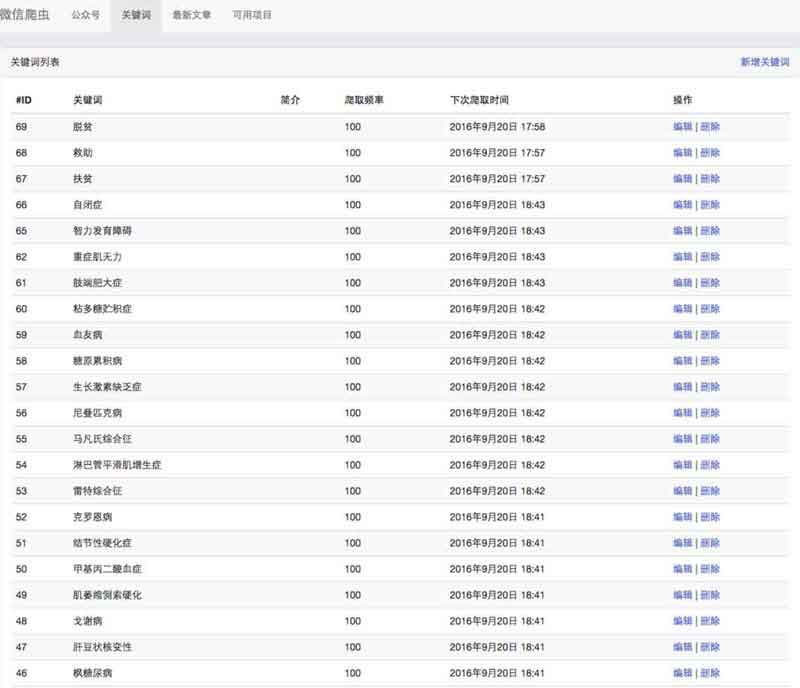 文章源自很文博客https://www.hinwi.com/很文博客-https://www.hinwi.com/11186.html
文章源自很文博客https://www.hinwi.com/很文博客-https://www.hinwi.com/11186.html
3) 已经爬取的微信文章文章源自很文博客https://www.hinwi.com/很文博客-https://www.hinwi.com/11186.html
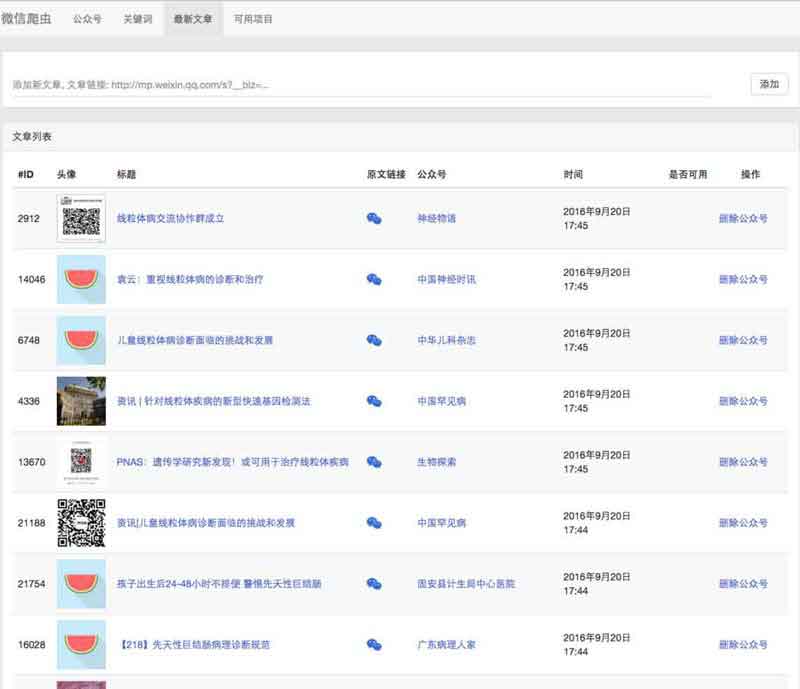
4) 查看文章,并标记是否可用
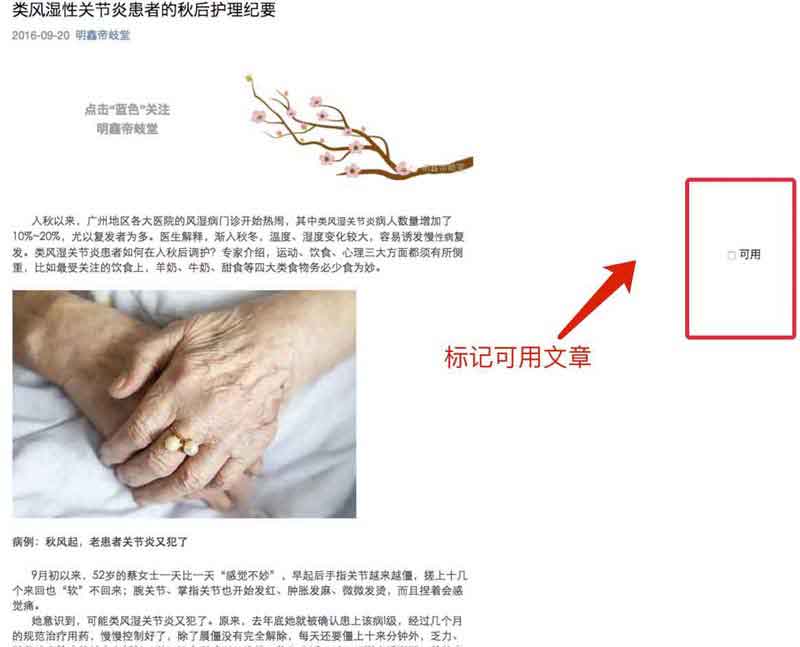
5) 控制爬取进程数
2.安装
1. PYTHON环境
检查python的版本,是否为2.7.x,如果不是,安装2.7.6。
如果是centos 6.x,升级python2.6到python2.7,参考教程
如果是centos 7.x,默认就是python2.7,不用升级
如果是mac osx,可以使用virtualenv,安装python2.7
2. 安装依赖包, CLONE代码
安装Mysql-python依赖
- #yum是Linux的包管理工具,Mac下有homebrew,Python有pip
- #一般Python会附带安装pip,如果没有安装的话可以安装一下
- $ sudo easy_install pip
- yum install python-devel mysql-devel gcc
- pip里没有python-devel mysql-devel这2个插件,所以装不上,后面运行也不影响,可以跳过。
- gcc装xcode就有了,如果不安装Xcode,可以用其他方式安装如homebrew
安装lxml依赖
- yum install libxslt-devel libxml2-devel
- pip里一样没有,可以通过homebrew来安装
- 我开始也是跳过了,但后面运行程序时报错,在stackoverflow找到这个答案,解决了,运行下面四个命令就行,需要先按照homebrew。
- brew install libxml2
- brew install libxslt
- brew link libxml2 --force
- brew link libxslt --force
- tips:安装这些的时候又报Xcode错误
- Error: Xcode alone is not sufficient on Sierra.
- Install the Command Line Tools:
- xcode-select --install
- 就用提示的这句安装xcode-select。自动搜索安装后,就能安装上面4个了
安装浏览器环境 selenium依赖.(如果是mac环境,仅需安装firefox, 但确保版本是 firefox 36.0,使用最新的版本会报错)
- #mac 直接跳过这3句,下载firefox安装
- yum install xorg-x11-server-Xvfb
- yum upgrade glib2 # 确保glib2版本大于2.42.2,否则firefox启动会报错
- yum install firefox # centos下安装最新的firefox版本
- Mac firefox 36.0 下载地址:https://ftp.mozilla.org/pub/firefox/releases/36.0.1/mac/
- 安装后偏好设置注意不要让其自动更新
clone代码,安装依赖python库
- $ git clone https://github.com/bowenpay/wechat-spider.git
- $ cd wechat-spider
- $ pip install -r requirements.txt
3. 创建MYSQL数据库
创建数据库wechatspider,默认采用utf8编码。(如果系统支持,可以采用utf8mb4,以兼容emoji字符。
- mysql> CREATE DATABASE `wechatspider` CHARACTER SET utf8;
4. 安装和运行REDIS
- $ wget http://download.redis.io/releases/redis-2.8.3.tar.gz
- $ tar xzvf redis-2.8.3.tar.gz
- $ cd redis-2.8.3
- $ make
- $ make install
- $ redis-server
5. 更新配置文件LOCAL_SETTINGS
在 wechatspider 目录下,添加 local_settings.py 文件,配置如下,注意修改成自己的配置,如数据库密码:
- # -*- coding: utf-8 -*-
- SECRET_KEY="xxxxxx"
- CRAWLER_DEBUG = True
- # aliyun oss2, 可以将图片和视频存储到阿里云,也可以选择不存储,爬取速度会更快。 默认不存储。
- #OSS2_ENABLE = True
- #OSS2_CONFIG = {
- # "ACCESS_KEY_ID": "XXXXXXXXXXXXXX",
- # "ACCESS_KEY_SECRET": "YYYYYYYYYYYYYYYYYYYYYY",
- # "ENDPOINT": "",
- # "BUCKET_DOMAIN": "oss-cn-hangzhou.aliyuncs.com",
- # "BUCKET_NAME": "XXXXX",
- # "IMAGES_PATH": "images/",
- # "VIDEOS_PATH": "videos/",
- # "CDN_DOMAIN": "XXXXXX.oss-cn-hangzhou.aliyuncs.com"
- #}
- # mysql 数据库配置
- DATABASES = {
- 'default': {
- 'ENGINE': 'django.db.backends.mysql',
- 'HOST': '127.0.0.1',
- 'NAME': 'wechatspider',
- 'USER': 'root',
- 'PASSWORD': '',
- 'OPTIONS':{
- 'charset': 'utf8mb4',
- },
- }
- }
- # redis配置,用于消息队列和k-v存储
- REDIS_OPTIONS = {
- 'host': 'localhost',
- 'port': 6379,
- 'password': '',
- 'db': 4
- }
6. 初始化数据库表
- $ python manage.py migrate
7. 启动网站
- python manage.py runserver 0.0.0.0:8001
访问 http://localhost:8001/。
创建超级管理员账号,访问后台,并配置要爬取的公众号和关键字
- python manage.py createsuperuser
8. 启动爬虫
mac需要4个terminal同时跑这些服务
- $ python bin/scheduler.py
- $ python bin/downloader.py
- $ python bin/extractor.py
- $ python bin/processor.py
3.其他
- 0. 中间出现权限问题permission failed,尝试加sudo提权root
- 1. mac默认安装了一个Python,并且安全保护机制导致安装依赖的时候权限不够而出错(即使加了sudo),可以安装使用virtualenv,对项目隔离出一个独立的Python
- 2.默认抓取当天能搜索的10条,但是有些公众号群发的不止10条,可以将wechat/downloaders.py里面的 [:10] 去掉。
- 3.单机版容易被检测爬虫,要求输入验证码,甚至限制ip,提示操作过于频繁,请稍后再试。
- 4.以上步骤执行成功,并能爬取文章后。可以参考以下部分配置生产环境。部署nginx前期先用nginx将域名www.mydomain.com转发到8001端口。部署supervisor脚本参考文件
supervisord.conf部署crontab脚本参考文件
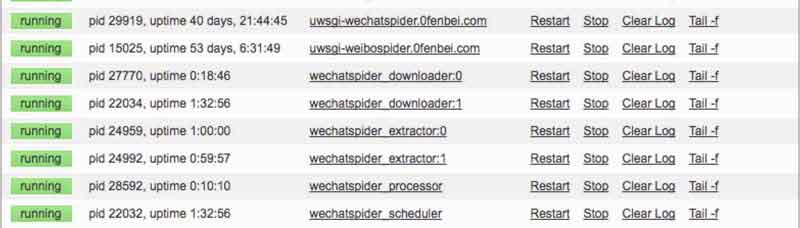
crontab - 5.进程管理,查看线程
需要自己安装和使用supervisor,并且自己修改/wechatspider/templates/nav.html,修改相应的a标签。
-
6. 后面的确是配置到头晕了,使用Intellij Idea 这个开发工具直接导入,配置独立Python env,安装依赖,运行,简单快捷。只是要注意一下:manager.py不能直接运行,需要配置script parameters:runserver 0.0.0.0:8001,爬虫的4个线程就可以直接运行。
-
7. 局限性和问题还是挺多,希望项目未来完善。而且数据采集本来就是专业活,普通用户还是使用专门的软件和插件来得快。






评论